인덱스를 쓰는 이유
특정 조건을 만족하는 데이터를 빠르게 찾기 위해
일반적으로 Full Text 검색을 하게 되면 O(N)의 시간이 걸리는데, B-tree 기반 인덱스를 사용한다면 O(logN)까지 줄어들게 된다.
복합 인덱스에서 설정을 잘못했다고 가정하자. INDEX(a)라는 테이블이 있고 쿼리는 a = 95 and b = 70 이렇게 있다고 가정할 때, a를 찾는 과정은 이전과 동일하게 O(logN)일 것이다. 하지만, b에는 인덱스가 걸려있지 않기 때문에 테이블을 전체 다 조회해야하고 이 때의 시간복잡도는 O(n)이라 전체 탐색과 다를 것이 없다.
따라서, INDEX(a, b)를 설정해줘야 한다.
복합 인덱스에서 column의 정렬 순서는 `a`, 그 다음에 `b` 를 정렬한다.
복합 인덱스 (a,b)가 걸려있을 때 b만 조회하려고 할 때에도 full text scan을 한다.
인덱스를 매번 생성해도 될까?
인덱스가 생성될 때 인덱스를 위한 부가적인 데이터가 생성된다. 따라서, 기존 테이블에 데이터가 write가 발생할 때마다 인덱스에도 변경이 발생하기 때문에 그로인한 `오버헤드`가 발생한다. 또한, `추가적인 저장 공간`을 차지한다.
그러므로, 불필요한 인덱스를 생성하지 말자.
또한, 데이터가 너무 적은 경우에는 굳이 인덱스를 사용하는 것과 full scan의 성능 차이가 없다.
full scan의 성능이 더 좋은 경우도 있는데,
SELECT * FROM customer WHERE mobile_career = 'SK';
이런 쿼리문이 있다고 할 때, 백만건의 데이터에서 조회하려는 데이터의 대부분이 SK라면 full scan이 더 빠를 수 있다.
이 때 인덱스와 full scan의 속도를 비교하여 실행시켜주는 역할은 optimzer가 대신 판단해준다.
B-tree
B tree의 최대 자녀 노드 수가 M개일 때, key 수는 M-1개가 된다.
3차 B tree라고 생각했을 때, 자녀 노드 갯수가 3개일 때 부모는 2개이므로 자녀 노드 갯수가 정해진다면 다른 값들도 자연스럽게 정해진다고 볼 수 있다.
삽입
B tree 삽입은 두가지 기준을 따른다.
- 추가는 항상 leaf 노드에 한다.
- 노드가 넘치면 가운데 (median) key를 기준으로 좌우 key들은 분할하고 가운데 key는 승진한다.
이러한 과정을 통해 삽입됐을 때 노드가 넘쳤을 때 key를 위로 올려주기 때문에, 모든 leaf 노드들은 같은 레벨에 존재한다.
이 것은 balanced tree라고도 이야기 할 수 있고, 검색에서의 worst/best case에서 O(logN)을 보장한다.
삭제
삭제도 마찬가지로,
- 삭제는 항상 leaf 노드에서 발생한다
- 삭제 후 최소 key보다 작아졌다면 재조정을 해준다.
root 노드에서 각 노드의 최소 key 수는 [M/2] - 1개 이다. 3차 B tree임을 가정하면, 최소 Key는 1개이고, 이것보다 작아진다면 재조정을 해준다는 의미이다.
삽입과 삭제같은 경우 한번씩 손으로 그려가며 시각화 했던것이 이해하는데 도움이 되었다.
그래서 왜 인덱스에 B tree를 사용할까?
B tree를 언급하기에 앞서, BST를 알아보자. BST의 삽입, 삭제, 조회의 시간복잡도는 평균적으로 O(logN)이나, 최악의 케이스에는 O(n)이 된다. 왜 그럴까?

해당 케이스가 BST의 worst case인데, 이런식으로 balance하지 않게 한쪽으로 치우치게 된다면 삽입, 삭제, 조회에 드는 시간 복잡도가 O(n)이 되버린다. 이런 경우에서 B tree의 성능이 BST보다 좋다고 할 수 있는것이다.
반면에, BST중에서도 스스로 균형을 잡는(balanced) AVL tree나 Red-Black tree가 있는데 해당 자료구조는 항상 balance를 유지하기 때문에 최악의 경우에도 O(logN)을 보장한다. 그렇다면, 왜 AVL tree를 안쓰고 B-tree를 쓰는걸까?

Computer System에 대한 이해

CPU: 프로그램 코드가 강제로 실행되는 곳
Main memory: 실행중인 코드들과 결과로 나온 데이터들이 상주하는 곳
Secondary storage: 프로그램과 데이터들이 영구적으로 저장되는 곳. 실행중인 데이터의 일부가 임시 저장되는 곳 `(메인 메모리의 용량이 작기 때문에 자주 사용되지 않는 데이터들의 일부를 임시로 저장 가능)`
Secondary storage의 특징으로는
- 데이터를 처리하는 속도가 가장 느리다.
- RAM의 평균 속도: 40 ~ 50인 반면, SSD와 HDD의 속도는 3 ~ 5, 0.2 ~ 0.3이다.
- 데이터를 저장하는 용량이 가장 크다.
- block 단위로 데이터를 읽고 쓴다.
DB의 데이터는 중요한 데이터이기 때문에, 컴퓨터를 꺼도 지속적으로 데이터가 내부에 남아있어야 한다. 그렇기 때문에 Secondary Stroage에 저장이 된다. 핵심 데이터의 몇 개는 Main memory에 올려놓고, 나머지는 Secondary storage에 넣어둔다.
결론적으로, DB에서 데이터를 조회할 때 secondary storage를 최대한 적게 조회하는 방식이 성능 면에서 좋다.
또한, block 단위로 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있다.
AVL tree vs B-tree 시간 복잡도 비교
먼저 비교하기 전에, 루트 노드만 메인 메모리에 올라와있고, 나머지 데이터들은 Secondary Storage에 존재한다고 가정하자.

`b = 5`인 데이터를 조회를 한다고 할 때, 처음에 루트 노드에서 시작을 하고,
6 -> 3 -> 4 -> 5 -> Secondary Storage에 5가 가르키는 값을 메인 메모리에서 읽어옴.
이를 통해 화살표가 4개 이므로, Secondary Storage에 4번 접근한 것을 알 수 있다.
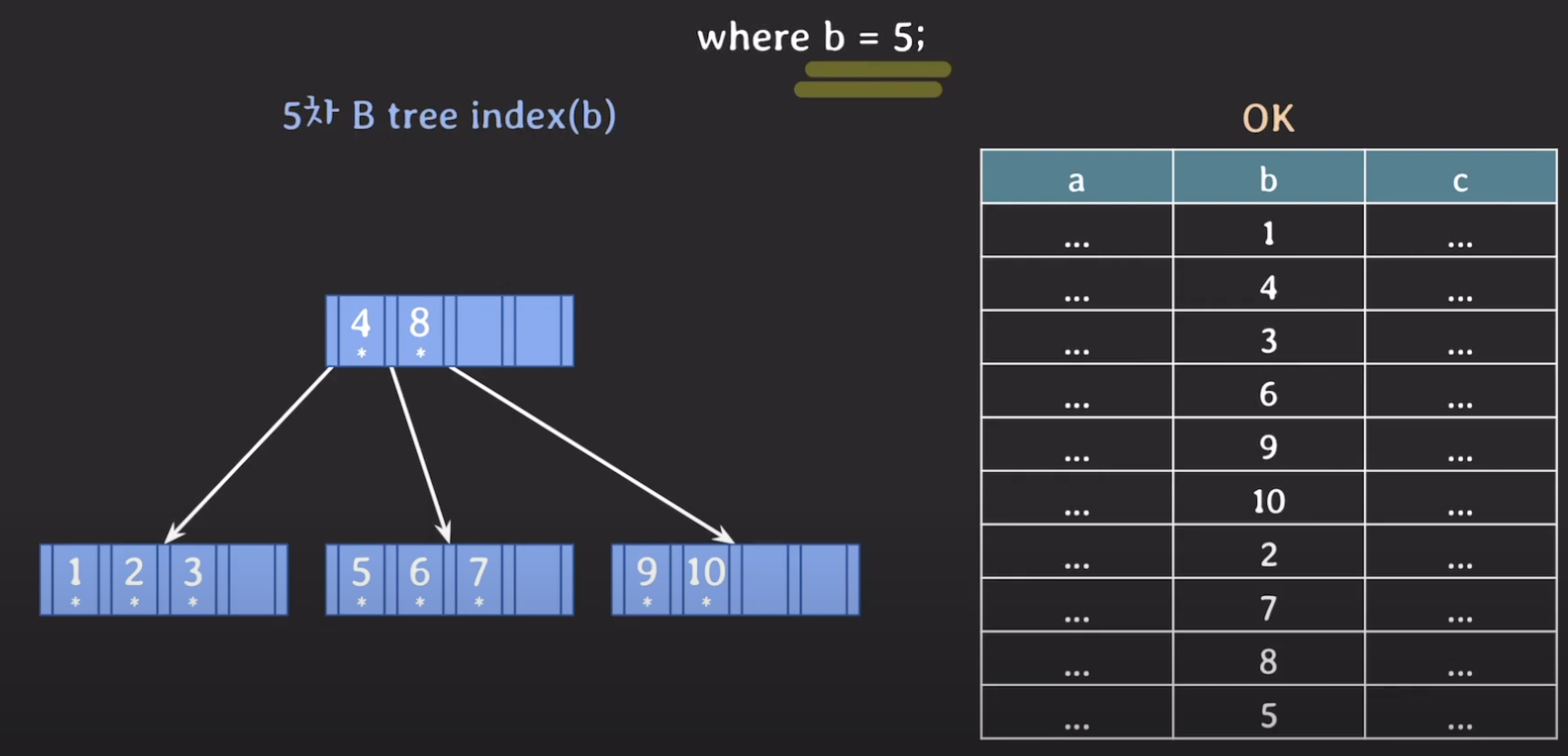
B tree에서도 `b = 5`인 데이터를 조회한다고 할 때, 4 < b < 8이므로,
root node -> 5,6,7 leaf node -> Secondary Storage에 5가 가르키는 값을 메인 메모리에서 읽어옴.
화살표가 2개 이므로, Secondary Storage에 2번 접근한 것을 알 수 있다.
결과
AVL tree: 4번 vs B tree: 2번 이므로, Secondary Storage에 적게 접근하는 B tree의 성능이 더 뛰어나다고 할 수 있다. 이러한 차이는 트리가 가질 수 있는 자녀 노드 수에 기인하는데, 5차 B-tree는 3 ~ 5개를 가질 수 있는 반면 AVL tree는 항상 1 ~ 2개 이다.
이를 통해 B tree는 데이터를 찾을 때 탐색 범위를 빠르게 줄일 수 있다는 강점이 있다.
또한, secondary storage에서는 block 단위로 데이터를 읽는다고 했는데, B tree인 경우엔 한 block에 [1,2,3]이 포함되는 반면,
| 1 | 2 | 3 |
AVL tree에서는 한 block에 [1]만 들어있다.
| 1 |
둘다 똑같은 공간을 차지하고 있지만 AVL 트리에선 공간이 좀 더 낭비되고 있는 것을 볼 수 있다. 따라서, B-tree가 block 단위에 대한 저장 공간 활용도 또한 좋은 것을 확인할 수 있다.
Hash Index
해쉬 인덱스를 사용한다면 삽입/삭제/조회를 O(1)에 수행할 수 있어 B-tree보다도 더 강력한 성능을 자랑하지만, equality (=) 조회만 가능하고 범위 기반 검색이나 정렬에는 사용될 수 없는 단점이 있다.
따라서, equality 조회만 한다고 가정할 때는 Hash Index를 사용하는 것이 효율적일 것이다.
- 일반적으로 인덱스는 수정이 잦은 테이블에선 사용하지 않기를 권합니다. 왜 그럴까요?
- 앞 꼬리질문에 대해, 그렇다면 인덱스에서 사용하지 않겠다고 선택한 값은 위 정책을 그대로 따라가나요?
- ORDER BY/GROUP BY 연산의 동작 과정을 인덱스의 존재여부와 연관지어서 설명해 주세요.
- 기본키는 인덱스라고 할 수 있을까요? 그렇지 않다면, 인덱스와 기본키는 어떤 차이가 있나요?
- 그렇다면 외래키는요?
- 인덱스가 데이터의 물리적 저장에도 영향을 미치나요? 그렇지 않다면, 데이터는 어떤 순서로 물리적으로 저장되나요?
- 우리가 아는 RDB가 아닌 NoSQL (ex. Redis, MongoDB 등)는 인덱스를 갖고 있나요? 만약 있다면, RDB의 인덱스와는 어떤 차이가 있을까요?
- (A, B) 와 같은 방식으로 인덱스를 설정한 테이블에서, A 조건 없이 B 조건만 사용하여 쿼리를 요청했습니다. 해당 쿼리는 인덱스를 탈까요?
참고자료
https://www.youtube.com/watch?v=liPSnc6Wzfk
https://github.com/VSFe/Tech-Interview/blob/main/04-DATABASE.md
Tech-Interview/04-DATABASE.md at main · VSFe/Tech-Interview
Contribute to VSFe/Tech-Interview development by creating an account on GitHub.
github.com